

This narrative documents a series of events and subsequent trouble-shooting undertaken in September 2018.
One of our internal servers (running Ubuntu 16.04.5 LTS) was showing errors (uncorrectable sectors) on its boot disk, a 7 year old Western Digital 10,000 rpm Velociraptor.
As we knew which data files were corrupted (and we were able to restore them from backups), instead of a full O.S. re-install onto a new hard drive, we performed a snapshot using Clonezilla in rescue mode (to skip bad blocks).
For a replacement hard drive we used what we had lying around – a brand new Seagate Barracuda 2TB ST2000DM008, manufactured in July 2018.
The restore went fine, with all services (including a Citadel mail server instance) back up and running. A few days later (with hindsight possibly too soon, but we had reason at the time) we upgraded this server to Ubuntu 18.04.1 LTS. Again all went OK, but after the weekend we noted that some files on this server being accessed over NFS from Ubuntu 18.04 clients were taking longer to write than they had prior to the disk replacement exercise.
Now, we were not confident whether the slow-down had occurred immediately after the disk swap, or only after the Ubuntu OS upgrade.
So we initially compared disk speeds, using Bonnie++.
mkdir /storage
bonnie++ -d /storage -s 16G -n 0 -m bonnie++-test -f -b -u root
echo "1.97,1.97,bonnie++-t,,,,,," | bon_csv2html > test.html
Seagate Barracuda ST2000DM008 2TB – 7,200rpm, 256MB cache, 1 platter, 2 heads, 16 logical r/w heads, avg latency 6ms
Western Digital WD4500HLHX Velociraptor 450GB – 10,000rpm, 32MB cache, 3x200GB platters (short-stroked), 5 heads => 90GB /side, avg latency 3ms
So, as far as writes are concerned, not hugely different, except for the latency on rewrites (read 8K, lseek back to the start of the block, overwrite the 8K with new data) which is much longer on the Barracuda.
So we took a step back and listed exactly where we were seeing slowdowns:
- Saving a 3MB text file from Vim running on a client to an NFS share on the server
- Saving a 600K spreadsheet from MS Excel running in a Windows7 VirtualBox guest to a VirtualBox Shared folded mapped to an NFS share on the server
- Copying (using command line cp command) a 14MB test file from a client desktop (local SSD) to an NFS share on the server (Velociraptor 14 seconds, Barracuda 75 seconds)
Focusing on NFS tuning, we removed ,rsize=32768,wsize=32768 entries from client NFS mounts. These had previously been added to work around some NFS bugs on our network of heterogeneous OS versions, but are no longer needed – NFS can now auto-negotiate optimum read/write block sizes. Looking at client mounts in /proc/mounts we could see the higher sizes negotiated. But this made no discernible difference to our file saving issues.
We then examined the vim file write more closely.
strace -to /tmp/vim.trace vim -i NONE -U NONE /nfsshare/file.txt
The trace file showed that Vim saves the file using a succession of 8k writes, 30 per second, giving a total write time for the 3MB file of 13 seconds.
The same Vim write, run locally on the server, was almost instantaneous.
Switching the client NFS mount to async certainly sped things up, but we couldn’t leave it like that (or so we thought).
After spending a few days intermittently chasing down dead-ends, we read:
https://www.avidandrew.com/understanding-nfs-caching.html
https://linux.die.net/man/5/nfs
https://linux.die.net/man/5/exports
And all became clear. So for us to configure our NFS shares so that writes can be cached by the server, but a client close() blocks until the server completes the write to physical disk, the correct settings are:
/etc/exports on server:
/testarea clientname(rw,sync,no_root_squash,no_subtree_check)
/etc/fstab on client:
servername:/testarea /testarea nfs4 rw,async,hard,intr,bg 0 0
Previously we had sync specified in both exports and fstab.
We never did get to the bottom of why we saw the five-fold speed difference between the Velociraptor and Barracuda when performing the 14MB file command line copy. At the time the NFS exports/fstab settings were identical.
And using gnome-disks to compare physical disk performance, we saw:

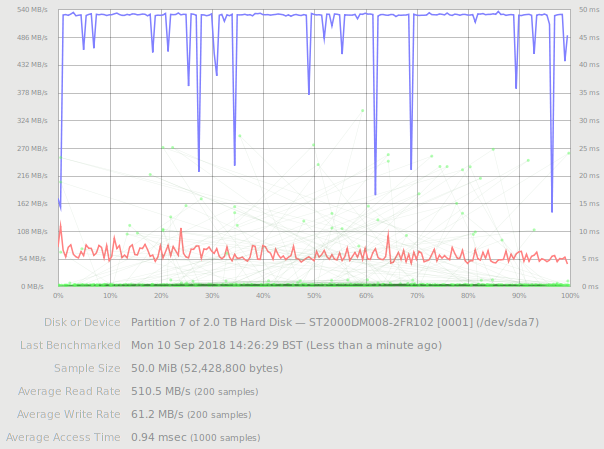
Which shows huge read throughput for the Barracuda, presumably because the reads were served from the onboard 256MB cache. But the part we’re interested in, the write speed, just shows the Velociraptor as 50% quicker – 92MB/sec vs 61MB/s. So why was the Barracuda five times slower in the copy test?



